分布式唯一ID的思考
Snowflake算法的一些问题
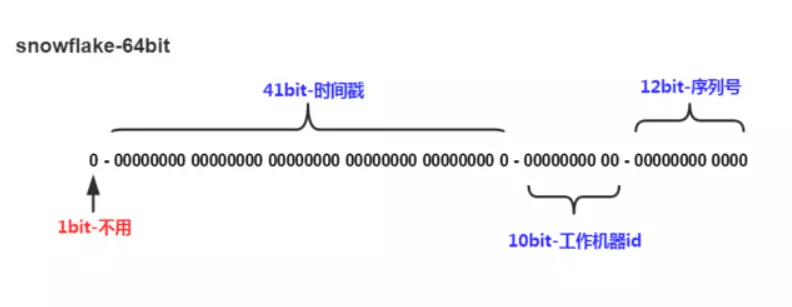
其核心算法是使用41bit作为毫秒数差值,10bit作为机器的ID,12bit作为毫秒内的流水号
理论上2^41毫秒可以使用 69 年,机器ID上限 1024,每毫秒最多可生成 4096 个唯一ID(409万/秒)
缺点:
- 机器时间回拨,这种情况可能造成ID重复。
- ID趋势递增,可能被竞争对手分析出每日ID增量。
解决办法:
- 发生时间回拨时,自动切换机器ID(要求配置冗余的机器ID,且有一定的分配机制)
- 调整比特位顺序和长度,比如采用 39位毫秒数差值,11位流水号,13位机器ID的,这样可以使用17年,支持8192台机器ID,每毫秒可产生 2048 个唯一ID(200万/每秒)。再调整一下机器ID的切换机制,可以一定程度增加ID的分析门槛。
参考:
伪共享(false sharing),并发编程无声的性能杀手
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 using1174@foxmail.com
文章标题: 分布式唯一ID的思考
文章字数: 288
本文作者: Jun
发布时间: 2019-09-12, 11:30:00
最后更新: 2019-09-12, 14:02:54
原始链接: http://yoursite.com/2019/09/12/分布式唯一ID的思考/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

