关于Protocol Buffers与FlatBuffers
FlatBuffers官网:http://google.github.io/flatbuffers/index.html
Protocol Buffers官网:https://developers.google.com/protocol-buffers/
参考结论
性能可以从几个方面来看,分别是编码性能,解码性能,和传输性能(主要是编码后的数据长度)。
初步结论
- 编码性能:flatbuf 的编码性能要比 protobuf 低得多,前者的性能大概只有后者的一半。在JSON、protobuf 和 flatbuf 之中,flatbuf 编码性能最差,JSON 介于二者之间。
- 编码后的数据长度:由于通常情况下,传输的数据都会做压缩,因而又分两种情况,编码后未压缩和压缩后的数据长度。flatbuf 编码后的数据,无论是压缩前还是压缩后,都比 protobuf 的数据长得多,前者的大概是后者的两倍。而 JSON 的数据在编码后未压缩的情况,是三者中最长的,但经 GZIP 压缩之后,实际的数据长度与 protobuf 的已经很接近了,同样比 flatbuf 的要短的多。不过对于某些场景,也会发现由于 protobuf 的二进制格式特性,导致经 GZIP 压缩之后的数据长度比 JSON 要长一些。
- 解码性能:flatbuf 是一种无需解码的二进制格式,因而解码性能要高许多,大概要比 protobuf 快几百倍的样子,因而比 JSON 快的就更多了。
综上,protobuf 在各个方面的平衡比较好。但如果使用场景是,需要经常解码序列化的数据,则有可能从 flatbuf 的特性获得一定的好处,就像 Facebook 之前那样。而 JSON 则胜在方便调试,生态完善,性能还行。
在内存空间占用这个指标上,FlatBuffers占用的内存空间比protobuf多。序列化时二者的cpu计算时间FB比PB快,反序列化时二者的cpu计算时间FB比PB快。FB在计算时间上占优势,而PB则在内存空间上占优(相比FB,这也正是它计算时间比较慢的原因)。Google宣称FB适合游戏开发是有道理的,如果在乎计算时间它也适用于后台开发。protobuf更适用于分布式计算领域。
另外,FB大量使用了C++11的语法,其从idl生成的代码接口不如protubuf友好。不过相比使用protobuf时的一堆头文件和占18M之多的lib库,FlatBuffers仅仅一个”flatbuffers/flatbuffers.h”就足够了。
进一步结论
- 在序列化后的存储空间占用方面,PB绝对优于FB,假设样本中数字较多时,PB的优势将更明显,因为zigzag的编码让数字变得更省空间。
- 在解析耗时方面,PB更优。虽然当数据层级较深而层级内数据量较小时,FB更有优势,而一旦层级内数据量变大,则PB会更省时间。为什么PB在这种场景下更快呢?分析这可能与FB的寻址方式有关,每个变量的读取都需要先去vtable查询偏移量,再根据偏移量移动指针读取数据,而偏移量都是基于vtable基准点计算得出的,每次读取都需要从基准点处重新寻址,而且读取过程没有顺序可言,当层级内数据较多时全部读取完毕需要更长时间。而PB不需要这么复杂的过程,直接顺序读取完毕,按k-v的对应关系赋值给相应变量即可。因此,FB更适合存储大块二进制数据,比如图片、游戏数据等;PB更适合短而复杂的通信协议。
- 在解析耗内存方面,FB比PB更优。这也是由存储方式以及协议的复杂度决定的,FB在访问数据时不需要创建临时内存,每个数据的存储位置可以认为是指定好的,直接读取内存就可实现反序列化,不需要复杂的解析逻辑,因此省去了很多中间对象的创建、内存申请;而PB是K-V存储方式,每个数据存放的先后顺序及位置是不能预知的,因此需要遍历过程去完成数据的解析,然后包装对应到对象,比FB多了解析过程。
实际传输场景下的选优
一次传输过程中数据传输前压缩(Gzip)和不压缩两种情况下,对比客户端总内存消耗和传输流量降低、传输耗时几方面。基于样本数据,取PB、FB与JSON进行对比。(样本数据60K)
- 不采用GZIP压缩直接进行二进制传输对内存开销降低影响明显,但反面影响是传输流量会增长1.3到1.7倍不等。考虑非WIFI用户的流量成本,建议仍然使用GZIP压缩的方式。
- FB+GZIP的传输流量JSON+GZIP方式还要多,且总内存耗费要高于PB+GZIP。
因此选择PB+GZIP。
另外,根据这篇文章,Facebook正在他们的Android应用程序中使用Flatbuffers。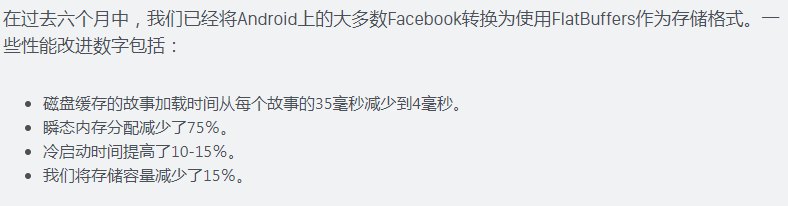
使用FlatBuffers
为什么要使用FlatBuffers
- 对序列化数据的访问不需要打包和拆包——它将序列化数据存储在缓存中,这些数据既可以存储在文件中,又可以通过网络原样传输,而没有任何解析开销;
- 内存效率和速度——访问数据时的唯一内存需求就是缓冲区,不需要额外的内存分配。 这里可查看详细的基准测试;
- 灵活性——它支持的可选字段意味着不仅能获得很好的前向/后向兼容性(对于长生命周期的游戏来说尤其重要,因为不需要每个新版本都更新所有数据);
- 最小代码依赖——仅仅需要自动生成的少量代码和一个单一的头文件依赖,很容易集成到现有系统中。再次,看基准部分细节;
- 强类型设计——尽可能使错误出现在编译期,而不是等到运行期才手动检查和修正;
- 使用简单——生成的C++代码提供了简单的访问和构造接口;而且如果需要,通过一个可选功能可以用来在运行时高效解析Schema和类JSON格式的文本;
- 跨平台——支持C++11、Java,而不需要任何依赖库;在最新的gcc、clang、vs2010等编译器上工作良好;
如何使用
- 编写一个用来定义你想序列化的数据的schema文件(又称IDL),数据类型可以是各种大小的int、float,或者是string、array,或者另一对象的引用,甚至是对象集合;
- 各个数据属性都是可选的,且可以设置默认值。
- 使用FlatBuffer编译器flatc生成C++头文件或者Java类,生成的代码里额外提供了访问、构造序列化数据的辅助类。生成的代码仅仅依赖flatbuffers.h;请看如何生成;
- 使用FlatBufferBuilder类构造一个二进制buffer。你可以向这个buffer里循环添加各种对象,而且很简单,就是一个单一函数调用;
- 保存或者发送该buffer
- 当再次读取该buffer时,你可以得到这个buffer根对象的指针,然后就可以简单的就地读取数据内容;
一个简单的Schemas(IDL)文件
namespace zl.persons;
enum GENDER_TYPE : byte
{
MALE = 0,
FEMALE = 1,
OTHER = 2
}
table personal_info
{
id : uint;
name : string;
age : byte;
gender : GENDER_TYPE;
phone_num : ulong;
}
table personal_info_list
{
info : [personal_info];
}
root_type personal_info_list;
注意:这里有table、struct的区别:
table是Flatbuffers中用来定义对象的主要方式,和struct最大的区别在于:它的每个字段都是可选的(类似protobuf中的optional字段),而struct的所有成员都是required。
table除了成员名称和类型之外,还可以给成员一个默认值,如果不显式指定,则默认为0(或空)。struct不能定义scalar成员,比如说string类型的成员。在生成C++代码时,struct的成员顺序会保持和IDL的定义顺序一致,如果有必要对齐,生成器会自动生成用于对齐的额外成员。如以下Schemas代码:
struct STest
{
a : int;
b : int;
c : byte;
}
在生成为C++代码之后,会补充两个用于padding的成员__padding0与__padding1:
MANUALLY_ALIGNED_STRUCT(4) STest {
private:
int32_t a_;
int32_t b_;
int8_t c_;
int8_t __padding0;
int16_t __padding1;
public:
STest(int32_t a, int32_t b, int8_t c)
: a_(flatbuffers::EndianScalar(a)), b_(flatbuffers::EndianScalar(b)), c_(flatbuffers::EndianScalar(c)), __padding0(0) {}
int32_t a() const { return flatbuffers::EndianScalar(a_); }
int32_t b() const { return flatbuffers::EndianScalar(b_); }
int8_t c() const { return flatbuffers::EndianScalar(c_); }
};
STRUCT_END(STest, 12);
table的成员顺序是动态调整的,这和struct有区别。在生成C++代码时,生成器会自动调整为最佳顺序以保证它占用最小的内存空间。
参考:
https://blog.csdn.net/yaokang522/article/details/38373993
https://capnproto.org/news/2014-06-17-capnproto-flatbuffers-sbe.html
https://www.jianshu.com/p/987c4d16c48b?from=timeline&isappinstalled=0
http://www.cnblogs.com/lizhenghn/p/3854244.html
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 using1174@foxmail.com
文章标题: 关于Protocol Buffers与FlatBuffers
文章字数: 2,272
本文作者: Jun
发布时间: 2018-07-18, 22:46:00
最后更新: 2018-07-18, 23:45:41
原始链接: http://yoursite.com/2018/07/18/关于Protocol-Buffers与FlatBuffers/版权声明: "署名-非商用-相同方式共享 4.0" 转载请保留原文链接及作者。

